Functional Programming for JavaScript People — Medium
Save article ToRead Archive Delete · Log in Log out
22 min read · View original · medium.com/@chetcorcos


Functional Programming for JavaScript People
Like many of you, I started hearing a lot about functional programming several months ago and I had no idea what it was. It was just a buzzword to me. Since then, I’ve explored the depths of functional programming and I thought I’d try to help demystify the newcomer who keeps hearing about all this stuff but doesn’t know what to make of it.
When talking about functional programming languages, there tends to be a few flavors: Haskell and Lisp, with plenty of debate over which is better. Although they are both functional languages, they are in fact quite different, each with their own trade-offs. By the end of this article, I hope you have a better idea of what those are. Both have their share of descendant languages as well. Two such languages that you may have heard of are Elm and Clojurescript, both of which compile into JavaScript. But before I get into the specifics of each language, my real goal is to instill in you some of the core concepts and patterns behind functional programming.
I highly recommend having at least one cup of coffee on hand before diving into this rabbit hole.
Pure Functions
At the heart of functional programming is the formal mathematics of describing logic: lambda calculus. Mathematicians like to describe programs as transformations of data which leads to the first concept — pure functions. Pure functions are functions without side-effects. Pure functions depend only on the inputs of the function, and the output should be the exact same for the same input. Here’s an example:
// pure function
const add10 = (a) => a + 10
// impure function due to external non-constants
let x = 10
const addx = (a) => a + x
// also impure due to side-effect
const setx = (v) => x = v
The impure function indirectly depends on x. If you were to change x, then addx would output a different value for the same inputs. This makes it hard to statically analyze and optimize programs at compile-time. But more pragmatically for JavaScript developers, pure functions bound the congnitive load of programming. When you’re writing a pure function, you only need to concern yourself with the body of the function. You don’t need to worry about externalities that could cause problems, like anything that could change x while when you’re writing the addx function.
Function Composition
One nice thing about pure functions is that you can compose them into new functions. One special operator used to describe programs in lambda calculus is compose. Compose takes two functions and “composes” them into a new function. Check it out:
const add1 = (a) => a + 1
const times2 = (a) => a * 2
const compose = (a, b) => (c) => a(b(c))
const add1OfTimes2 = compose(add1, times2)
add1OfTimes2(5) // => 11
The compose is analogous to the preposition “of”. Notice the order of the arguments and how they’re evaluated: add one of times two — the second function is evaluated first. Compose is the opposite of perhaps a more intuitive function you might be familiar with from unix called pipe, which accepts an array of functions.
const pipe = (fns) => (x) => fns.reduce((v, f) => f(v), x)
const times2add1 = pipe([time2, add1])
times2add1(5) // => 11
With function composition, we can now build more complicated data transformations by joining together (composing) smaller functions. This article does a great job of showing you how function composition can help you process data in a clean an concise way.
Pragmatically speaking, composition is a better alternative to object oriented inheretance. Here’s a contrived, but real-world example for you. Suppose you need to create a greeting for your users.
const greeting = (name) => `Hello ${name}`Great! A simple, pure function. Then, your project manager says you now have some more data about your users and wants you to add prefixes to the names. So you go ahead and write this code:
const greeting = (name, male=false, female=false) =>
`Hello ${male ? ‘Mr. ‘ : female ? ‘Ms. ‘ : ‘’} ${name}`
This code isn’t terrible, but what if we start adding more and more booleans for other categories such as “Dr.” or “Sir”? What if we add suffixes as well such as “MD” or “PhD”? And what if we want to have a casual greeting that says “Sup” instead of “Hello”? Well now things have really gotten out of hand.
Adding booleans like this to a function isn’t exactly object oriented inheritance, but its a similar situation to when objects have properties and methods that get extended and overridden as they inherit. So as opposed to adding boolean options, lets try to use function composition:
const formalGreeting = (name) => `Hello ${name}`
const casualGreeting = (name) => `Sup ${name}`
const male = (name) => `Mr. ${name}`
const female = (name) => `Mrs. ${name}`
const doctor = (name) => `Dr. ${name}`
const phd = (name) => `${name} PhD`
const md = (name) => `${name} M.D.`formalGreeting(male(phd("Chet"))) // => "Hello Mr. Chet PhD"This is much more manageable and easier to reason about. Each function does a one simple thing and we’re able to compose them together easily. Now, we haven’t handled all the cases here, and for that we can use our handy pipe function!
const identity = (x) => x
const greet = (name, options) => {
return pipe([
// greeting
options.formal ? formalGreeting :
casualGreeting,
// prefix
options.doctor ? doctor :
options.male ? male :
options.female ? female :
identity,
// suffix
options.phd ? phd :
options.md ?md :
identity
])(name)
}
Another benefit of using pure functions and function composition is its much easier to trace errors. Whenever you get an error, you should be able to see a stack trace through every function down to the source of the bug. In object oriented programming, its often quite confusing because you don’t always know the state of the rest of the object which led to the bug.
Function Currying
Function currying was invented by the same guy who invented Haskell — his name: Haskell Curry (correction: named after Haskell Curry). Function currying is when you call a function with fewer arguments than it wants and that function returns another function to accept the rest of the arguments. This is a good article that explains it in more detail, but here’s a simple example using the Ramda.js curry function.
In the example below, we create a curried function “add”, which takes in two arguments. When we pass one argument, we get back a partially applied function we call “add1” which only takes one argument.
const add = R.curry((a, b) => a + b)
add(1, 2) // => 3
const add1 = add(1)
add1(2) // => 3
add1(10) // => 11
In Haskell, all functions are automatically curried. There are no optional or default arguments.
Pragmatically, function currying is really convenient when using functions with map, compose and pipe. For example:
const users = [{name: 'chet', age:25}, {name:'joe', age:24}]
R.pipe(
R.sortBy(R.prop('age')), // sort user by the age property
R.map(R.prop('name')), // get each name property
R.join(', '), // join the names with a comma
)(users)
// => "joe, chet"This makes data processing feel very declarative. Notice how the code reads just like the comments!
Monads, Functors, and Fancy Words
Monads and functors are just fancy words for things you already know. If you want to get a firm understanding, I’d highly suggest reading this article which does a great job of explaining with awesome graphics. But this stuff really isn’t all that complicated.
Monads are pretty interesting though. Monads can be thought of as a container for a value, and to open up the container and do something to the value, you need to map over it. Here’s a simple example:
// monad
list = [-1,0,1]
list.map(inc) // => [0,1,2]
list.map(isZero) // => [false, true, false]
The important thing about monads and functors is that mathematicians have been researching these ideas in category theory. This provides us not only a framework for understanding programs, but algebraic theorems and proofs we can use to statically analyze and optimize our code when it’s compiled. This is one of the main benefits of Haskell — the Glasgow Haskell Compiler is a feat of human ingenuity.
There are all kinds of theorems and identities expressed in category theory. For example, here’s a simple identity:
list.map(inc).map(isZero) // => [true, false, false]
list.map(compose(isZero, inc)) // => [true, false, false]
When map is compiled, it uses an efficient while loop. In general this is a O(n) operation (linear time), but there is still overhead associated with incrementing the pointer to the next item in the list. So the second version is actually twice as performant. These are the kind of transformations that Haskell does to your code at compile-time to make it blazingly fast — and there’s a really cool trick to doing this that I’ll explain later.
To expand on monads just a little, there’s a very interesting monad called the Maybe monad (sometimes called Option or Optional in Swift). In Haskell, theres no such thing as null or undefined. To express something as being potentially null, you need to wrap it in a monad so the Haskell compiler knows what to do with it.
The Maybe monad is a union type that’s either Nothing or Just something. In Haskell you’d define a Maybe like this:
type Maybe = Nothing | Just x
The lowercase x just means any other type.
Being a monad, you can .map() over a Maybe to change the value it contains! When you map over a Maybe, if it of type Just, then we apply the function to the value and returns a new Just with that new value. If a the Maybe is of type Nothing, then we return Nothing. In Haskell, the syntax is quite elegant and uses pattern matching, but in JavaScript you might use a Maybe like this:
const x = Maybe.Just(10)
const n = x.map(inc)
n.isJust() // true
n.value() // 11
const x= Maybe.Nothing
const n = x.map(inc) // no error!
n.isNothing // true
This monad may not seem terribly useful in your Javascript code, but its interesting to see why its so useful in Haskell. Haskell requires you to define what to do in every edge-case of your program, otherwise it won’t compile. When you make an HTTP request, you get back a Maybe type because the request may fail and return nothing. And if you didn’t handle the case in which the request failed, then your program won’t compile. This basically means that it’s impossible to get runtime errors. Maybe your code does the wrong thing, but it doesn’t just magically break like things tend to do in Javascript.
This is a big selling point for using Elm. The type system and compiler enforces that your program will run without runtime errors.
Thinking about code in the context of monads and algebraic structures will help you define and understand your problem in a structured way. For example, an interesting extention of Maybe is the this Railway-Oriented Programming concept for error handling. And observable streams are monads as well for dealing with asynchronous events.
There are all kinds of fancy monads and many other words that I don’t myself fully understand. But to keep all the lingo consistent, there are specifications like fantasy-land and the typeclassopedia which try to unify different concepts in category theory for the purpose of writing idiomatic functional code.
Referential Transparency and Immutability
Another implication of leveraging all this category theory and lambda calculus stuff is referential transparency. Its really hard for mathematicians to analyze logical programs when two things that are the same aren’t equal to each other. This is an issue all over the place in Javascript.
{} == {} // false
[] == [] // false
[1,2] == [1,2] // falseNow imagine having to do math in a world without referential transparency. You wouldn’t be able to write proofs that say that an empty array is the same things as an empty array. What should matter is only the value of the array, not the reference pointer to the array. And so functional programming languages resort to using deep-equals to compare values. But this isn’t terribly performant, so there are some neat tricks to make this comparison quicker that leverages references.
Before moving on, I just want to make one thing clear: in functional programming, you cannot mutate a variable without changing its reference. Otherwise, the function performing the mutation would be impure! Thus, you can assure that if two variables are referentially equal, their values must be equal as well. And since we can’t mutate variables in-place, then we have to copy those values into a new memory location every time we want to transform it. This is a huge performance loss and results in garbage thrashing. But the solution is using structural sharing (persistent data structures).
A simple example of structural sharing is a linked list. Suppose you only keep a reference to the end of the list. When comparing two lists, you can first start by seeing if the ends are referentially equal. This is a nice shortcut because if they are equal, then you’re done — the two lists are the same! Otherwise, you’ll have to start iterating through the items in each list to see if their values are equal. To efficiently add a value to this list, rather than copying entire the list into a new set of memory, you can simply add a link to a new node and keep track of the reference at the new tip. Thus, we’ve structurally shared the previous data structure in a new data structure with a new reference and we’ve persisted the previous data structure as well.
The generalized data structure for doing these immutable data transformations is called a hash array mapped trie (HAMT). This is exactly what Immutable.js and Mori.js do. Both Clojurescript and Haskell have this built into the compiler, although I’m not sure it’s implemented in Elm yet.
Using immutable data structures can give you performance gains, and help keep your sanity. React assumes props and state are always immutable so it an do an efficient check to see if the previous props and state are referentially equal to the next props and state before unnecessarily re-rendering. And in other circumstance, using immutable data simply helps to ensure that values aren’t changing without you realizing it.
Lazy Evaluation
Lazy evaluation is sort of a general term that covers more specific concepts like thunks and generators. Lazy evaluation means exactly what you think it does: don’t do something until you absolutely have to, be lazy and procrastinate as long as possible. One analogy is to suppose you have a large, possibly infinite, amount of dishes to wash. Rather than put all the dishes in the sink and wash them at once, let’s be lazy and just take one dish at a time.
In Haskell, the true essence lazy evaluation is a little easier to understand, so I’m going to start there. First, we need to understand how programs evaluate. Pretty much every language you’re used to uses innermost reduction. Innermost reduction looks like this:
square(3 + 4)
square(7) // evaluated the innermost expression
7 * 7
49
This is a sane and reasonable way of evaluating programs. But now, let’s consider outermost reduction:
square(3 + 4)
(3 + 4) * (3 + 4) // evaluated the outermost expression
7 * (3 + 4)
7 * 7
49
Outermost is clearly less efficient — we’ve had to compute 3 + 4 twice, so the program took 5 steps instead of 4. This is no good. But Haskell keeps a reference to each expression and shares these references as they’re passed down to parent expressions through the outermost reduction. Thus, when 3 + 4 is evaluated the first time, the reference to this expression now points to the expression, 7. Thus we get to skip the duplicate step.
square(3 + 4)
(3 + 4) * (3 + 4) // evaluated the outermost expression
7 * 7 // both reduced at the same time due to reference sharing
49
Fundamentally, lazy evaluation is outermost evaluation with reference sharing.
Haskell does all this stuff under the hood for you, and what that means is you can define things like infinite lists. For example, you can recursively define an infinite list of ones as 1 joined with itself.
ones = 1 : ones
Suppose you have a function take(n, list) which takes the first n elements of a list. If we used innermost reduction, we’d recursively evaluate list forever, because it’s infinite. But instead, with outermost reduction, we lazily evaluate ones for just as many ones as we need!
However, since JavaScript and most other programming languages use innermost reduction, the only way we can replicate these constructs is by treating arrays as functions. For example:
const makeOnes = () => {next: () => 1}
ones = makeOnes()
result.next() // => 1
result.next() // => 1Now we’ve effectively created a lazily evaluated infinite list based on the same recursive definition. Lets create an infinite list of natural numbers:
const makeNumbers = () => {
let n = 0
return {next: () => {
n += 1
return n
}
}
numbers = makeNumbers()
numbers.next() // 1
numbers.next() // 2
numbers.next() // 3In ES2015, there’s actually a standard for this and they’re called function generators.
function* numbers() {
let n = 0
while(true) {
n += 1
yield n
}
}Laziness can give you huge performance gains. For example, check out Lazy.js operations per second compared to Underscore and Lodash:

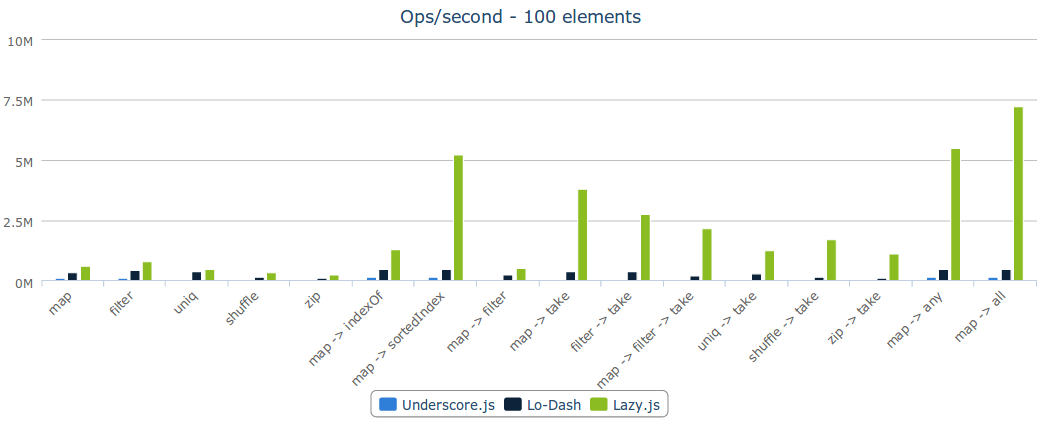
Here’s a great example of why that is (given by the Lazy.js website). Suppose you have a huge array of people and you want to perform some transformations on it:
const results = _.chain(people)
.pluck('lastName')
.filter((name) => name.startsWith('Smith'))
.take(5)
.value()
The naïve way of doing this would be to pluck all the lastNames off, filter the entire array, and then take just the first 5. This is what Underscore.js and most other libraries do. But with generators, we can lazily evaluate the expression by going one value at a time until we have 5 last names that start with “Smith”.
What’s amazing about Haskell is that this is all baked into the language by using outermost reduction and reference sharing. Every list is inherently lazy. In Javascript, you should probably just use Lazy.js, but if you wanted to create something like this of your own, you just need to understand that each step above returns a new generator. To get values out of a generator, you need to ask for them by calling .next(). The chain method turns the people array into a generator, and each transformation accepts a generator and returns another generator. Then, when you call .value() it simply calls .next() repetitively until there are no more values left. And .take(5) will make sure that you aren’t processing more values than you need to!
Now remember that theorem earlier:
list.map(inc).map(isZero) // => [false, true, false]
list.map(compose(isZero, inc)) // => [false, true, false]
Lazy evaluation, inherently does these kind of optimizations for you.
Clojure Patterns and Features
I’ve talked a lot about Haskell so I want to explain where Clojure fits in to all of this. Clojure has referential transparency, immutable data types, and you cannot mutate variables in-place except for special transactional types called atoms. This is incredibly convenient sometimes when compared to Haskell, where you would be forced to scan values over a stream simply to record values in an associative array to recall elsewhere. Clojure also does not have a strong type system or an insanely powerful compiler like the Glasgow Haskell Compiler. And there is such thing as null in Clojure. That said, functional patterns are strongly encouraged and hard not to use in Clojure.
There are two things about Clojure that really stand out to me though: Everything is a primative data type in Clojure, called EDN — the Clojure version of JSON. Rather than having objects and types, everything is just some primitive data structure that’s interpreted however you want. For example, in JavaScript, we have native Date objects. But what happens when you want to serialize a date to JSON? Well you need to create your own custom serializer/deserializer. In Clojure, you might express a date as an associative array with a timestamp and a timezone (unless you’re using the Java implementation). Any string formatting functions just assume the same data structure. So in Clojure, there’s a strong emphasis on data, data transformations, and data processing. Everything is data.
The other really cool thing about Clojure is that code is data. Clojure is a Lisp which stands for list processing. The language is just an interpretation of lists where the first item in a list is a function and the rest of the items are arguments — which is why they like to say there’s a Lisp in every language. What’s so cool about Lisps, though, is you can create insanely powerful macros. The macros most people are used to are text substitution macros, where you generate code using some kind of string template. And there’s a cool library for doing this in Javascript called Sweetjs. But in Clojure, since the code itself is just a list, you can inspect the code as a list at compile-time, transform the code, and then evaluate it! This is really convenient for wiring up repetitive boilerplate and allows you to essentially create whatever syntax you want to express something. To do the same thing in JavaScript, you’d need to get very familiar with Babel Plugins and the JavaScript Abstract Syntax Tree (AST) and create your own transpiler. But in Clojure, the AST is just a list!
One of the big features of Clojure is the core.async library for handling asynchronous communication, and it has a beautiful way of using macros. In the following example, we create a channel, and the go function is actually a macro.
(def echo-chan (chan))
(go (println (<! echo-chan)))
(>!! echo-chan "ketchup")
; prints ketchup
What’s amazing here is that go is actually interpretting its argument as a list to generate a bunch of nasty async code that nobody wants to write. It’s looking for <! which is a symbol for essentially subscribing to the channel. Then it generates some code that does the job. Look at all this nasty code that we don’t have to write or deal with:
user=> (macroexpand ‘(go (println (<! echo-chan))))
(let* [c__6888__auto__ (clojure.core.async/chan 1) captured-bindings__6889__auto__ (clojure.lang.Var/getThreadBindingFrame)] (clojure.core.async.impl.dispatch/run (clojure.core/fn [] (clojure.core/let [f__6890__auto__ (clojure.core/fn state-machine__6712__auto__ ([] (clojure.core.async.impl.ioc-macros/aset-all! (java.util.concurrent.atomic.AtomicReferenceArray. 8) 0 state-machine__6712__auto__ 1 1)) ([state_8650] (clojure.core/let [old-frame__6713__auto__ (clojure.lang.Var/getThreadBindingFrame) ret-value__6714__auto__ (try (clojure.lang.Var/resetThreadBindingFrame (clojure.core.async.impl.ioc-macros/aget-object state_8650 3)) (clojure.core/loop [] (clojure.core/let [result__6715__auto__ (clojure.core/case (clojure.core/int (clojure.core.async.impl.ioc-macros/aget-object state_8650 1)) 1 (clojure.core/let [inst_8644 println inst_8645 echo-chan state_8650 (clojure.core.async.impl.ioc-macros/aset-all! state_8650 7 inst_8644)] (clojure.core.async.impl.ioc-macros/take! state_8650 2 inst_8645)) 2 (clojure.core/let [inst_8644 (clojure.core.async.impl.ioc-macros/aget-object state_8650 7) inst_8647 (clojure.core.async.impl.ioc-macros/aget-object state_8650 2) inst_8648 (inst_8644 inst_8647)] (clojure.core.async.impl.ioc-macros/return-chan state_8650 inst_8648)))] (if (clojure.core/identical? result__6715__auto__ :recur) (recur) result__6715__auto__))) (catch java.lang.Throwable ex__6716__auto__ (clojure.core.async.impl.ioc-macros/aset-all! state_8650 clojure.core.async.impl.ioc-macros/CURRENT-EXCEPTION ex__6716__auto__) (clojure.core.async.impl.ioc-macros/process-exception state_8650) :recur) (finally (clojure.lang.Var/resetThreadBindingFrame old-frame__6713__auto__)))] (if (clojure.core/identical? ret-value__6714__auto__ :recur) (recur state_8650) ret-value__6714__auto__)))) state__6891__auto__ (clojure.core/-> (f__6890__auto__) (clojure.core.async.impl.ioc-macros/aset-all! clojure.core.async.impl.ioc-macros/USER-START-IDX c__6888__auto__ clojure.core.async.impl.ioc-macros/BINDINGS-IDX captured-bindings__6889__auto__))] (clojure.core.async.impl.ioc-macros/run-state-machine-wrapped state__6891__auto__)))) c__6888__auto__)
Conclusion
That’s basically everything I’ve learned about functional programming in the last few months. I hope that really helps people, especially the JavaScript community, write better code and inevitably create even more awesome things!
As for the never-ending debate on Haskell vs Clojure, I think it’s impossible to say which is better because they’re different. Haskell is the the fundamentals of functional programming. Haskell people literally call themselves programming fundamentalists. Haskell is rigid, specific, bulletproof, and ridiculously fast and compact. Clojure is malleable, abstract, and empowering. You can do anything in Clojure because its written on the JVM (and you can do pretty much anything in Java). In Clojure you can build off decades of work in tried and tested Java algorithms. Clojure also has a unique culture of creative programmers behind it with really cool libraries like Overtone and Quill.
As far as the Javascript world, I would love to see things moving more into the realm of pure functions. I don’t ever want to see this again. And let’s also get in the habit of only using const types rather than the mutable var or let.
Two of my absolute favorite JavaScript libraries are Ramda and Flyd. But Ramda isn’t lazy and doesn’t play nice with Immutable.js. I’d really like to see a library that combines all of these concepts — persistent / shared / immutable data structures with curried, lazily evaluated, composable utility functions.
And I’d also like to see libraries using a more consistent language for describing things — the new ES2015 Promises API, for example, uses .then as opposed to .map even though a Promise is totally a monad! This means, that you can’t use Ramda for processing data inside native promises because R.map won’t work. I think the aptly named Fantasyland specification is a grand ideal because it tries to unify the language that all programming data structures speak. If all these libraries like Ramda, Lodash, Lazy.js, Immutable.js, and even the native data primitives like promises use this common language, we can use reuse way more code. You could swap out your native Javascript arrays for Immutable.js lists without having to rewrite all the data processing code you’re using in Ramda or Lazy.js.
Anyways, I hope you enjoyed reading this. Please let me know if you didn’t understand something or if something made a lot of sense to you so I can improve my writing/mind-barfing — ccorcos@gmail.com.
Happy Hacking