Consequence Management Systems — Track Changes
Save article ToRead Archive Delete · Log in Log out
9 min read · View original · trackchanges.postlight.com
Consequence Management Systems


{kind=link}
There’s an activist and columnist named Shaun King. He writes from a progressive position about social justice and race, which makes him a target of much criticism on and off the Internet.
King has a column in the Daily News, which is a tabloid newspaper in NYC perhaps best-explained in opposition to the NY Post (it’s not founded by Alexander Hamilton, not owned by Rupert Murdoch, often goes left where the Post goes right—and struggles in the same way as every legacy-print media business).
Last Tuesday, April 19th, King was accused of plagiarism by another publication, the Daily Beast. It appeared that he’d run whole paragraphs of their pieces as his own. Plagiarism is the original sin of journalism, and King is professionally controversial, so there was an explosion of interest on social media. After what appeared to be a few hours the Daily News announced that they’d found the culprit—an unnamed editor—who’d made “egregious and inexplicable” errors in formatting the posts. They promptly fired the editor.
When Shaun King posted to Twitter screenshots of the columns as he’d emailed them, my content-management instincts began to tingle. In his emails to his editor, King was citing whole paragraphs—blog-style, indented. Blockquotes. Here’s an example:

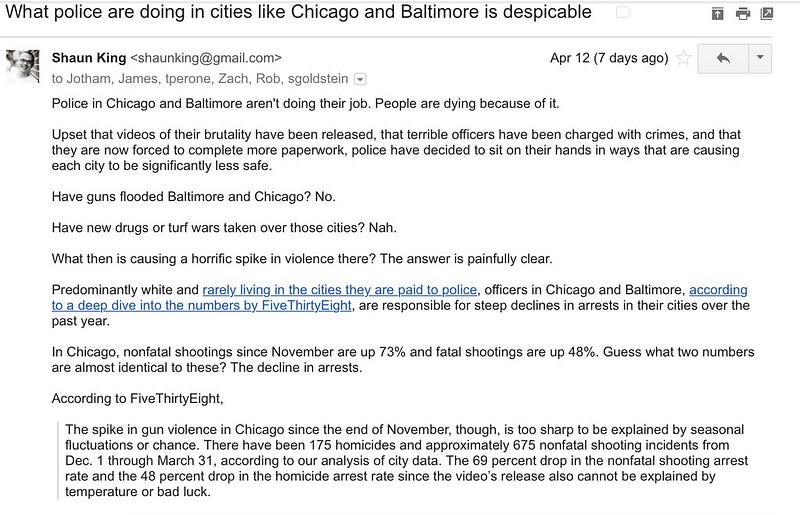
These columns were getting cut out of email and pasted…somewhere. Well doesn’t cut-and-paste work that way? The simple answer is: No. Cutting and pasting formatted text into a content management system results in an explosion of complexity and edge cases. It would be entirely possible for formatting information to be lost. And from there, well, it’s a little bit of human error to something that would look exactly like plagiarism.
It turns out the editor was Jotham Sederstrom. (Semi-disclosure: I don’t know Sederstrom but I know his wife—Elizabeth Spiers. Like hundreds—maybe thousands—of people who work in the nerdier quarters of NYC media, I’ve worked with Elizabeth and respect her hustle.) He wrote a public apology and explanation of what happened. According to him, yes, it was a mix of human error and software problems. Sederstrom wrote (emphasis added as bolding):
In all honesty, the controversy — a f — up on my part, to put it bluntly — comes down to two unintentional, albeit inexcusable, instances of sloppy editing on my part and a formatting glitch that until Tuesday I had no idea was systematically stripping out large blocks of indented quotations each time I moved Shaun’s copy from an email to The News’ own Content Management System, or “CMS” as it’s called in media parlance.
In those two cases where no citation or hyperlink appeared in the column, I believe I likely cut attribution from the top of Shaun’s quoted text with the intention of pasting them back inside the block — only to get distracted with another of the many responsibilities I juggled as an editor. On any given day I was tasked with editing not only Shaun’s column but roughly 20 other news stories from five reporters, all of whom filed early and often. Add to that a whiplash-inducing crescendo of breaking news, a handful of administrative responsibilities and the chaos typical of most newsrooms, and it’s easier to fathom how frequently focus can snap from one second to the next. This is not an excuse, but here I take issue with Jim Rich’s assertion that these mistakes were “inexplicable.” They can happen easily if you’re not paying extreme attention to detail at every moment. Many of us in the news industry are increasingly under pressure to deliver an ever higher volume of stories with ever fewer resources and let’s just say, that doesn’t help. I don’t say that to absolve myself of blame, but to illustrate how this happened with no intention on my part to damage Shaun’s reputation or the paper’s.
Oof. That’s a complicated situation.
Soon after, the editor Max Read wrote about the issue in New York’s “Following”:
If we all wrote directly inside the content-management systems where we publish our work to the world, this would be less of a problem. But very few of us do (for one thing, they generally don’t save your work). From assignment to publication, text can pass through several different editors, some of them made to handle richly formatted text in one particular way, some made to handle it in another, and some of them … not really made for that at all. A story that begins in Microsoft Word might then be pasted into Gmail and emailed to an editor using Outlook; from Outlook it might be pasted again into Google Docs, before finally being pasted into the text box of a proprietary CMS, for example. In the process, it will likely have picked up (or lost) stray bits of HTML formatting — odd <div> and <span> tags used by one text editor but not another — even if the text as written remains intact.
I was chatting about all this on Twitter and I was surprised at some of the assumptions that people were making in their replies (it was a good reminder of how much I live inside a media/technology bubble). People seemed to think:
- That editorial CMSes could be trusted to basically “work.” But many, especially at older media companies, are deeply flawed disasters that are slow, prone to break, and introduce risk and error into the publishing process.
- That writers were responsible for their own posts. But the buck stops with editors, not with writers.
- That writers should use Markdown or write in the CMS themselves. But it’s hard to train thousands of writers from all over the world to do something new.
- That this was an unusual circumstance. But editors often move things around after publication or run quiet “due to an editing error” corrections (this includes me!); it’s just that this one had 50,000 kilowatts of social media sunshine beaming down on top of it.
Meanwhile Austin Smith, the CEO of Alley Interactive—which builds CMSes—blogged about the issue. He saw it as a call to arms for product developers to do better:
And this is why Jotham’s firing ought to be a clarion call to developers and product owners across media. We are a protected class, because we are eminently employable by other industries, yet we choose to work in news. Much like the reporters and editors I know, I work in news because I believe in the accessibility of information and the absolute necessity of surveilling and reporting on the quotidian machinations of power. Product staff are not in the line of fire, yet our decisions impact editors and reporters who are in the line of fire every day — and in creating a CMS, we define the basic parameters of their daily life.
If you want a taste of the technical issues involved in cutting-and-pasting into a web browser (and most CMSes run on the web), this post on Medium, entitled, “Why ContentEditable is Terrible/Or: How the Medium Editor Works,” is exemplary. At its essence, that post says: The principles that you can apply to make computer software reliable are exceedingly difficult to apply to editing rich text on the World Wide Web.
It’s a foundational issue — here be dragons. Which means it’s not just difficult to solve, but expensive. Medium (another disclosure: I’m an advisor here) has a very experienced web engineering team, and after many years of hard work has done a pretty good job at making it possible to cut-and-paste a very, very limited subset of HTML into a web page—and it is riding that horse to glory.
Track Changes is not the corporate newsletter with all the answers. I wish it were. But there’s no single software, human, process, or social fix that could have avoided this situation. There’s no single bad actor, either, as much as it would be convenient for all involved if Sederstrom were just some attribution-hating monster sneakily setting up his writers for public humiliation. He’s obviously not. He was, he explains, a person in a hurry who missed an incredibly important detail.
That’s why it’s so fascinating, and troubling. This probably could have happened to any editor. And the solutions are expensive and complex—and as anyone shipping software inside a media organization can tell you, “fixing the software” is a complex, multivariate equation involving limited budgets and countless tradeoffs, and often involves fixing the people and the process as much as writing new code. You’re met with much resistance.
Sederstrom owned his mistake pretty fully; his Medium post is a case study in apologies and I hope that when I next screw something up in public I can do half as well (key note for future disasters: He posted, then stepped back and stayed quiet—i.e. he put down the shovel). Meanwhile the Daily Beast and the Daily News both look…bad, basically, and Shaun King is in the impossible situation of protecting himself from totally spurious accusations of plagiarism while trying not to throw his friendly editor too far under the bus. A bad week for all involved. All over some HTML tags.
Below the fold
Letter
From: Erin McKean
To: Postlight
Hi folks!
What you ask for here:
Conclusion: My ideal search interface that uses only existing capabilities of Google would:
Provide a definition of the term searched-for, when possible;
Provide a link to the Wikipedia page for the term, when available;
List associated terms that can be used as filters; and
Just show me a bunch of pictures.
Then below that you could have the old-school search results.
Is kind of what Wordnik tries to do for individual words … we don’t (yet) link to Wikipedia (although we do show Wiktionary info), and our Flickr images are dependent on the vagaries of the Flickr API (we’re not caching their results) but it’s verrrry close (I think).
Would love to know what you think!
Today’s links
- Today’s JavaScript library: moment-timezone — Timezone support for moment.js.
- Today’s North Korean slogan: “Let us defend the 7th Congress of the Workers’ Party of Korea by strengthening the political and military might of the People’s Army in every way!”
- Today’s Creative Commons media link: OpenStax College.
- Today’s old-school Unix fortune: “Language is a virus from outer space. -William Burroughs.”
- Today’s variety of religious experience: Thai Dhammayuttika Nikaya.
- Today’s freely available programming book: Isabelle/HOL — A Proof Assistant for Higher-Order Logic by Tobias Nipkow and Lawrence C. Paulson and Markus Wenzel (PDF).
- Today’s React component: coffee-react-transform — Provides React JSX support for Coffeescript.